* Sharding(샤딩)
샤딩은 수평 분할(Horizontal Partitioning)과 동일하며, 인덱스의 크기를 줄이고, 작업 동시성을 늘리기 위한 것이다.
수평 분할(Horizontal Partitioning)이란 스키마(schema)가 같은 데이터를 두 개 이상의 테이블에 나누어 저장하는 디자인을 말한다.
가령 같은 주민 데이터를 처리하기 위해 스키마가 같은 '서현동주민 테이블'과 '정자동주민 테이블'을 사용하는 것을 말한다.
데이터베이스를 샤딩하게 되면 기존에 하나로 구성될 스키마를 다수의 복제본으로 구성하고 각각의 샤드에 어떤 데이터가 저장될지를 샤드키를 기준으로 분리한다.
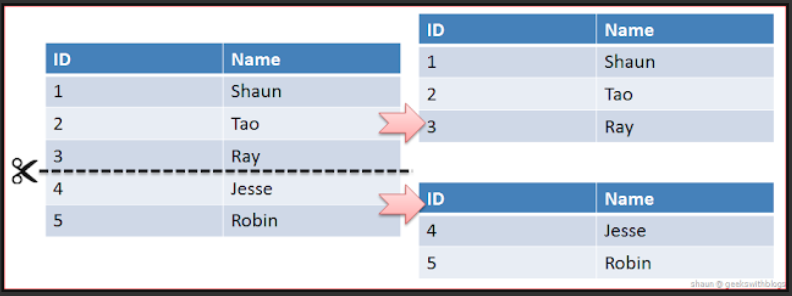
* Sharding(샤딩)의 단점
프로그래밍적, 운영적인 복잡도가 높아진다.
즉, 샤딩을 시작하기 전에 샤딩을 피하거나 지연시킬 수 있는 방법을 찾는게 우선이다.
1. 좀더 고스펙의 컴퓨터를 사용한다.
2. Read(Select) 명령이 많다면 Cache나 Database Replication을 적용한다.
3. Table의 일부 Column만 사용한다면 수직 분할(Vertically Partitioning)을 사용한다 / Cold & Hot data를 사용한다.
참고) Database Replication이란?
2개 이상의 DBMS를 Master와 Slave로 나누어 동일한 데이터를 저장한다.
Master DB는 Insert, Update, Delete의 기능을 수행하고, Slave DB에 실제 데이터를 복사한다.
Slave DB 시간이 오래걸리는 Select문의 기능을 수행하여 전체적인 Select문 성능을 향상시킨다.
참고) Cold / Hot Data 란? Naver D2 :: Cold Storage 소개
Hot data : 자주 사용되는 데이터
Cold data : 드물게 사용되거나 아예 사용되지 않는 데이터
Cold Storage : 에너지 절감을 위해 연산 능력에서 손해를 보더라도 낮은 가격과 저전력으로 자주 사용되지 않는 데이터를 처리하는 데이터 저장 장치 및 시스템
* Sharding(샤딩)의 주요 관점
분산된 DB에서 어떻게 Data를 읽어올 것인지?
분산된 DB에 Data를 어떻게 잘 분산시킬지?
>> Shard Key를 어떻게 정의하는지에 따라 달라진다.
Case 1. Algorithm Sharding

Database id를 단순하게 나누어 샤딩하는 방식
Sharding Key는 hash(key) % NUM_DB 같은 방식
* 장점
같은 값을 가지는 key-value 데이터베이스에 적합하다.
* 단점
Cluster를 포함하는 Node 갯수가 변하게 되면 Resharding이 필요하다.
Hash Key로 분산되기 때문에 공간에 대한 효율이 부족하다.
Case 2. Dynamic Sharding

클라이언트는 Locator Service에 접근하여 Shard Key를 얻는다.
* 장점
Cluster가 포함하는 Node 갯수가 변하면 Shard Key를 추가하기만 하면 된다.
>> 확장에 유연하게 대처가능하다.
* 단점
Data Relocation시에는 Locator Service의 Shard key Table도 일치시켜야 한다.
Locator에 의존할 수 밖에 없는 구조이다.
Case 3. Entity Group

RDBMS의 Join, Index, Transaction을 사용하여 복잡도를 줄이는 방식과 유사
동일한 파티션의 관련 엔티티를 저장하여 단일 파티션 안에서 추가 기능을 제공하는 방식
* 장점
하나의 물리적인 Shard에 쿼리를 진행하면 효율적이된다.
사용자의 증가에 따른 확장성이 좋은 파티셔닝이다.
* 단점
특정 파티션간 쿼리가 자주 요구되는 경우가 있다.
* 참고자료
'∙Databases' 카테고리의 다른 글
| [정보처리기사]관계 데이터베이스 모델과 언어 (0) | 2020.06.30 |
|---|---|
| [정보처리기사]데이터베이스 개념 및 모델링 (0) | 2020.06.30 |
| [Databases] 카카오뱅크는 어떻게 MySQL를 사용할까? (0) | 2018.12.13 |
| [Databases] Oracle ANSI SQL과 INNER/OUTER JOIN 차이 (1) | 2018.12.13 |