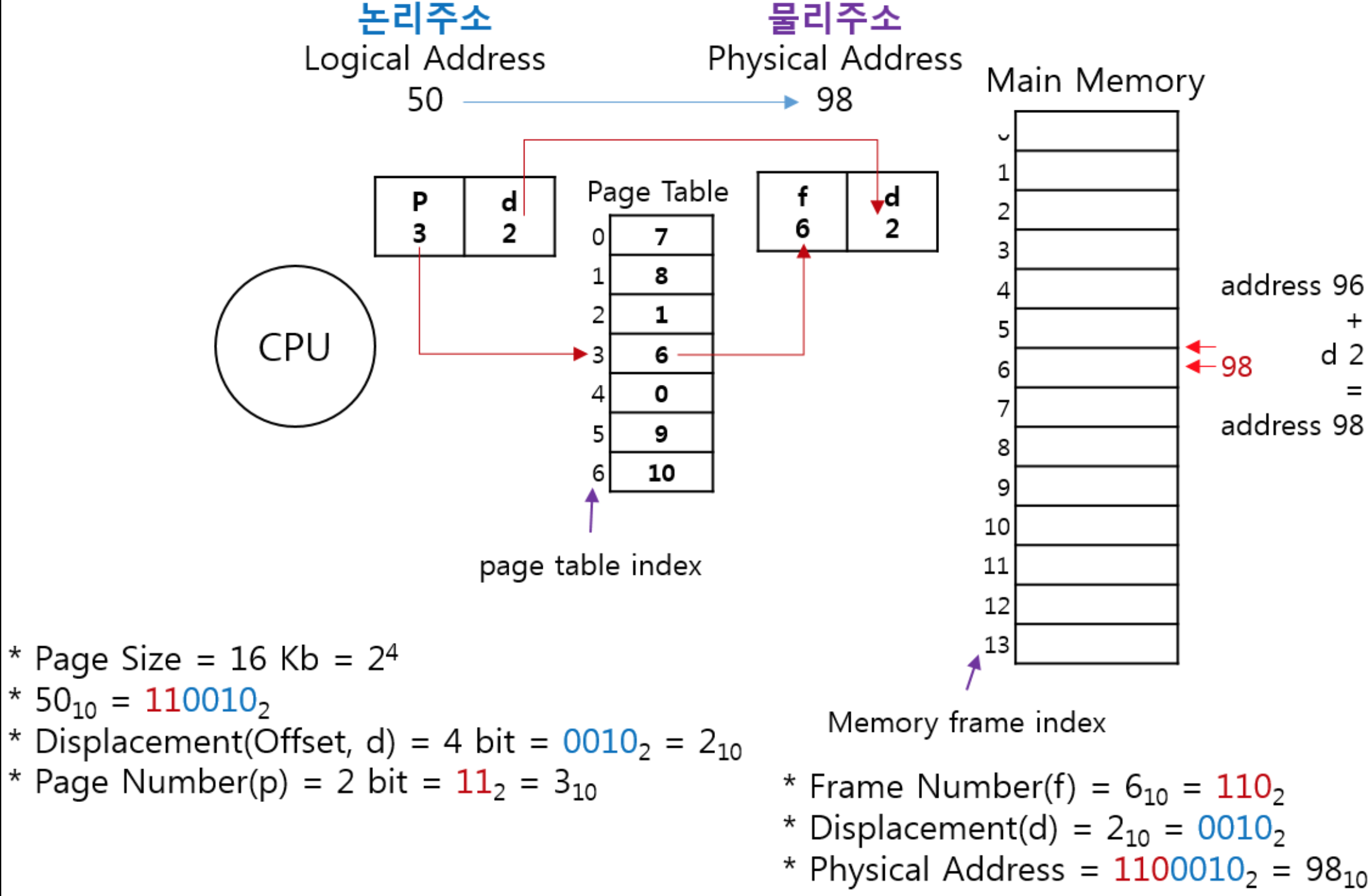
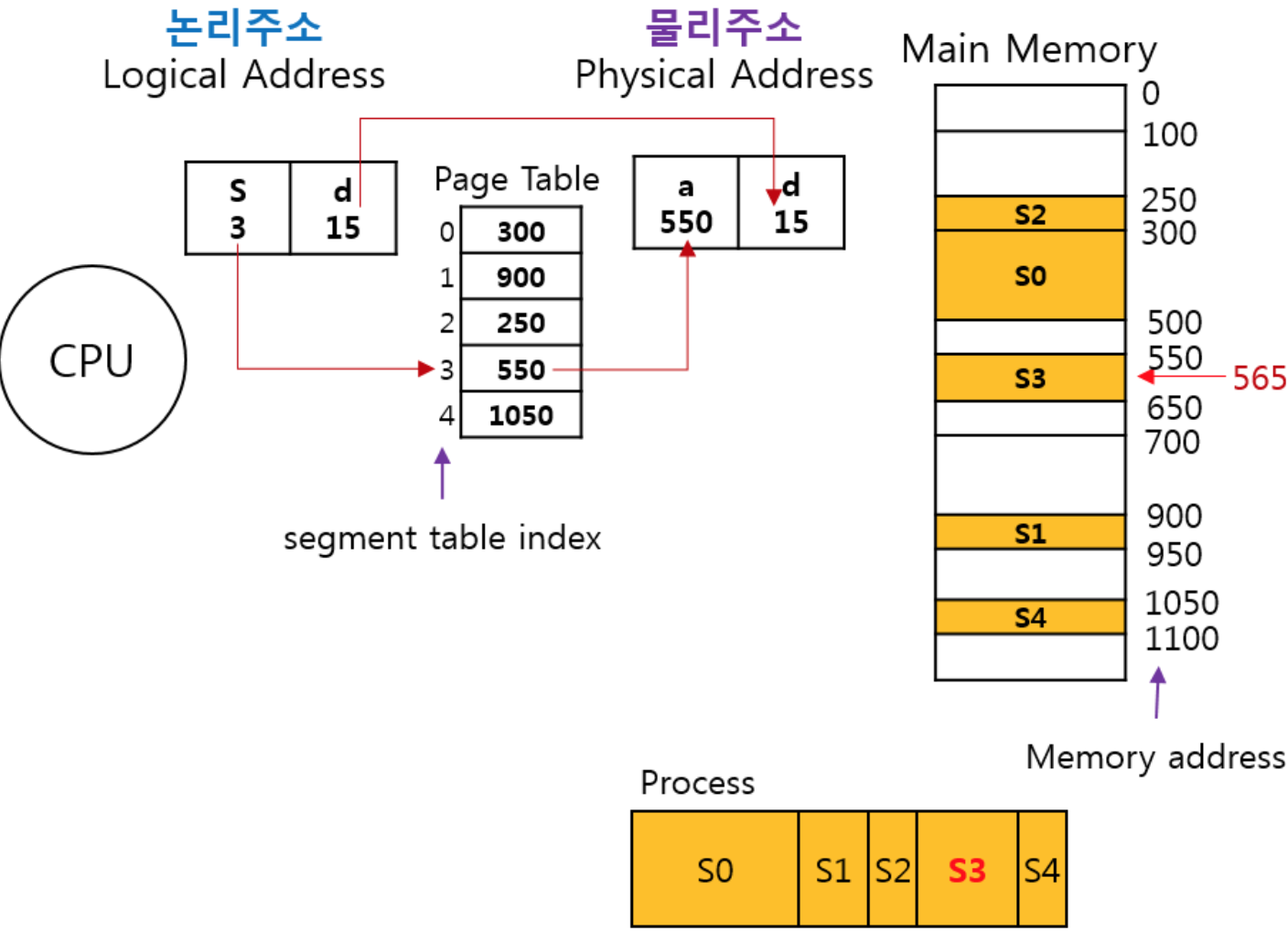
프로세스 동기화 배경
- 프로세스가 병행 또는 병렬로 실행될 때 여러 프로세스가 공유하는 데이터의 무결성이 유지되어야 한다.
- 병행 프로세스는 다중 처리 시스템이나 분산 처리 시스템에서 중요 개념으로 사용
임계 구역
- 임계구역 안에서는 공유 변수를 변경, 테이블 갱신, 파일 쓰기 등의 작업을 수행한다.
- 임계구역에는 하나의 프로세스만 접근할 수 있으며, 해당 프로세스가 자원을 반납해야 다른 프로세스가 자원 및 데이터를 사용할 수 있다.
- 한 프로세스가 자신의 임계구역에서 수행하는 동안에는 다른 프로세스들은 그들의 임계구역에 들어갈 수 없다.
임계구역 문제 해결 방법
- 상호 배제 기법
- 특정 프로세스가 공유 자원을 사용하고 있을 경우 다른 프로세스가 해당 공유 자원을 사용하지 못하게 제어하는 기법
- 두 개의 프로세스 기준 : 피터슨 알고리즘(두 프로세스가 두 개의 데이터 항목을 공유하여 자원을 사용하는 방법)
- 여러 개의 프로세스 기준 : Lamport의 빵집 알고리즘(각 프로세스에 번호를 부여하여 자원을 사용하도록 하는 방볍)
- 진행
- 자신의 임계구역에서 실행되는 프로세스가 없고 자신의 임계구역으로 진입하려는 프로세스가 있다면 잔류 구역에서 실행 중이지 않은 프로세스들만 임계영역에 진입 대상이 되고, 이 선택은 무한정 연기되지 않음!
- 한계 대기
- 프로세스가 자기의 임계구역에 진입하려는 요청을 한 후로부터 요청이 허용될 때까지 다른 프로세스들이 임계영역에 그들 자신의 임계구역에 진입을 허용하는 횟수의 한계가 필요하다.
Mutex Lock(상호 배재)
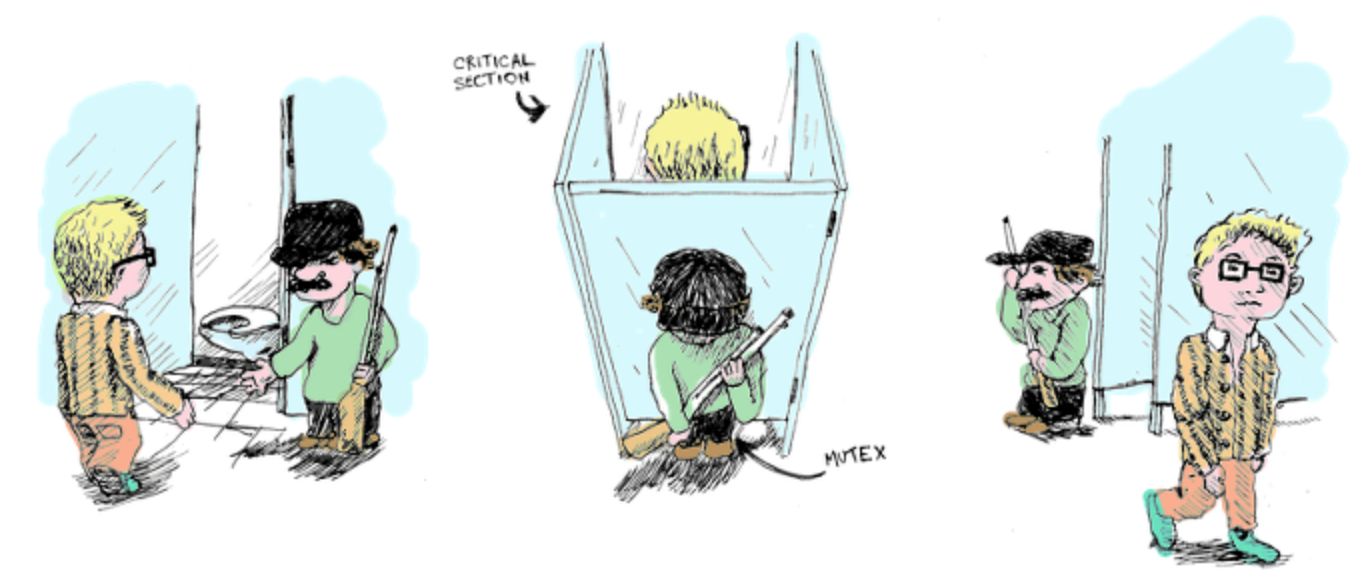
- Mutex가 지켜주는 덕에 화장실을 한명만 사용할 수 있다.
- 즉, Mutex는 임계구역을 보호하고 프로세스간 경쟁을 방지하기 위해 사용
- boolean available 변수를 사용 => 락의 가용 여부 표시
1
2
3
4
5
6 | do {
//Lock 획득
임계구역
//Lock 반환
나머지 구역
} while(true);
|
세마포어(Semaphore)
- Mutex와 유사하게 동작하지만 프로세스들이 자신들의 행동을 더 정교하게 동기화 할 수 있는 방법 제공
- 각 프로세스에 제어신호를 전달하여 순차적으로 진행하기 위한 동기화 구현
- 세마포 S = 정수 변수, wait(s)와 signal(s)로만 접근이 가능하다. S = 0인 경우 모든 자원이 사용 중을 의미
1
2
3
4
5
6 | //wait(S) => 상호배재 보장
//임계구역에 진입하기 전에 확인
if (S <= 0) //누군가 사용하고 있다면
S가 양수가 될 때까지 현재 프로세스를 list에서 기다림
else //임계 구역에 진입이 가능하다면
S = S - 1;
|
1
2
3
4
5
6 | //Signal(S) => 진행 보장
//임계구역을 떠날 때 실행
if (자원 반환전에 list에서 기다리는 프로세스가 있다면)
그 중 한개 프로세스를 임계 구역 진입
else //list에서 기다리는 프로세스가 없다면
S = S + 1;
|
Mutex와 세마포어의 차이
Mutex(상호 배재)
- Critical Section을 가진 쓰레드들의 Running time이 서로 겹치지 않게 각각 단독으로 실행되게 하는 기술
- Mutex 객체를 두 쓰레드가 동시에 사용할 수 없다. (1개의 쓰레드만 Critical Section에 접근 가능하도록 하는 기술)
- cf) Critical Section : 각 프로세스에서 공유데이터를 엑세스하는 프로그램 코드부분
세마포어(Semaphore)
- 공유된 자원의 데이터를 여러 프로세스가 접근하는 것을 막는 것
- 만약, 화장실 칸이 4개라면 4개의 프로세스는 사용 가능하고, 나머지 프로세스는 대기해야 한다.
고전적인 동기화 문제
- 생산자-소비자 문제
- 생산자가 데이터를 생산하여 입력된 경우에만 접근하도록 구성하는 방식
- 생산자는 꽉찬 버퍼를 생산하고 소비자는 비어있는 버퍼를 생산한다.
- 읽기-쓰기 문제
- 두 Reader가 동시에 공유 데이터를 접근하는 것은 허용하나, 동시에 Writer를 허용하지 않는 방식
- Writer보다 Reader 요청이 많은 경우 병행성을 높일 수 있다.
- 식사하는 철학자 문제
- 5명의 철학자들은 생각하고 먹는 일을 수행(철학자 : 프로세스, 젓가락 : 자원)
- 철학자는 양쪽의 젓가락을 사용하여 식사를 하고, 식사를 마친 철학자는 젓가락을 내려놓고 다시 생각한다.
- 철학자는 2개의 젓가락을 손에 쥐어야 식사를 할 수 있고, 한 번에 하나씩 잡을 수 있다.
- 옆 사람이 식사중이면 젓가락 잡는 것을 대기한다.
5명의 철학자가 동시에 식사를 하게 되면 모두 왼쪽 포크만을 가지게 되고 오른쪽 포크를 대기하는 교착 상태(Deadlock)이 발생한다.
이를 방지하기 위한 방법은 대표적으로 3가지이다.
- 최대 4명의 철학자들만이 테이블에 앉을 수 있도록 한다. => 젓가락이 하나 남기 때문에 어떤 철학자는 식사가 가능하다.
- 한 철학자가 동시에 두개의 젓가락을 모두 집을 수 있을 때만 젓가락을 집도록 허용한다.(즉, 임계구역 안에서만 젓가락을 집어야 한다)
- 비대칭 해결안을 사용한다.(홀수 번 철학자는 왼쪽, 짝수 번 철학자는 오른쪽 젓가락부터 집는다)
교착상태(DeadLock)
- 상호 배제에 의해 나타나는 문제점으로 둘 이상의 프로세스들이 자원을 점유한 상태에서 서로 다른 프로세스가 점유하고 있는 자원을 요구하며 무한정 기다리는 현상
예방 기법
- 상호 배재 부정 : 한 번에 여러 개의 프로세스가 공유 자원을 사용할 수 있도록 한다.
- 점유 및 대기 부정 : 프로세스가 실행되기 전 필요한 모든 자원을 할당해 프로세스 대기를 없애거나 자원이 점유되지 않은 상태에서만 자원을 요구하도록 한다.
- 비선점 부정 : 자원을 점유하고 있는 프로세스가 다른 자원을 요구할 때 점유하고 있는 자원을 반납하고, 요구 자원을 사용하기 위해 기다리게 한다.
- 환형 대기 부정 : 자원을 선형 순서로 분류해 고유 번호를 할당하고, 각 프로세스는 현재 점유한 고유 번호보다 앞이나 뒤 한쪽 방향으로만 자원을 요구하도록 한다.
회피 기법(Dijkstra 제안한 은행원 알고리즘)
- 안정 상태 : 모든 프로세스가 교착상태를 일으키지 않으면서 각 프로세스가 요구한 최대 요구량만큼 필요한 자원을 할당해 줄 수 있는 상태
- 불안정 상태 : 교착상태의 필수 조건으로 교착상태가 발생할 수 있는 상태
은행원 알고리즘 : 안전상태를 유지할 수 있는 요구만을 수락하고 불안전 상태를 초래할 사용자의 요구는 나중에 만족될 수 있을 때까지 계속 거절하는 알고리즘
- 각 프로세스마다 할당할 수 있는 최대 자원을 계산한다.
- 각 프로세스마다 자원을 할당한 후에도 안전 상태를 유지할 수 있는지 확인하고 자원을 할당한다.
- 추가적인 자원을 할당해도 안전 상태를 유지할 수 있다면 자원을 할당할 수 있다. 하지만 불안전상태가 된다면 교착상태가 되므로 거절한다.
- Available : 각 종류별로 가용한 자원의 개수, Available[i] = k 라면 R[i] 를 K개 사용할 수 있다는 뜻
- Max : 각 프로세스가 최대로 필요로 하는 자원의 개수, Max[i,j] = k 라면 Process[i]가 R[j]를 K개까지 요청할 수 있다는 뜻
- Allocation : 각 프로세스에게 현재 나가있는 자원의 개수, Allocation[i,j] = k 라면 현재 Process[i]가 R[j]를 K개 사용 중이라는 뜻
- Need : 각 프로세스가 향후 요청할 수 있는 자원의 개수, Need[i,j] = k라면 Process[i]가 향후 R[j]를 K개 요청할 수 있다는 뜻
자원 요청 알고리즘
- 만약 Request[i] <= Need[i] 이면 2단계로 이동, 아니면 시스템에 있는 개수보다 더 많이 요청했기 때문에 오류로 처리
- 만약 Request[i] <= Available[i] 이면 3단꼐로 이동, 아니면 요청한 자원이 지금 없으므로 Process[i]는 기다려야 한다.
- Process[i]에게 할당한 것처럼 시스템 상태정보를 바꿔 본다.
- Available = Available - Request[i]
- Allocation[i] = Allocation[i] + Request[i]
- Need[i] = Need[i] - Request[i]
- 만약, 이렇게 바뀐 상태가 안전하다면 Process[i]에게 자원을 할당한다. 그렇지 않다면 상태를 원상태로 되돌리고 Request[i]가 만족될 때까지 기다린다.
예를 통해 알아보자. 프로세스 P와 A 자원 10개, B 자원 5개, C 자원 7개가 있을 때 다음과 같은 예시가 있다고 가정하자.
| Process | | Allocation | | | Max | | | Need | |
|---|
| Type | A | B | C | A | B | C | A | B | C |
| P[0] | 0 | 1 | 0 | 7 | 5 | 3 | 7 | 4 | 3 |
| P[1] | 2 | 0 | 0 | 3 | 2 | 2 | 1 | 2 | 2 |
| P[2] | 3 | 0 | 2 | 9 | 0 | 2 | 6 | 0 | 0 |
| P[3] | 2 | 1 | 1 | 2 | 2 | 2 | 0 | 1 | 1 |
| P[4] | 0 | 0 | 2 | 4 | 3 | 3 | 4 | 3 | 1 |
Need 값은 Max - Allocation 으로 구할 수 있으며 이 경우 남은 자원 수는 다음과 같다.
| | Available | |
|---|
| A | B | C |
| 10 - (0+2+3+2+0) = 3 | 5 - (1+0+0+1+0) = 3 | 7 - (0+0+2+1+2) = 2 |
여기서 P[1]이 A 자원 1개와 C 자원 2개를 추가로 요청한다고 가정해보자. 이 때의 Request[1] = (1,0,2) 가 된다.
- Request[i] <= Need[i]를 검사한다. (1,0,2) <= (1,2,2)이므로 조건을 만족한다.
- Request[i] <= Available[i]를 검사한다. (1,0,2) <= (3,3,2) 이므로 조건을 만족한다.
- Process[i]에게 할당한 것처럼 시스템 상태정보를 바꿔 본다.
- Available[1] = Available[1] (3,3,2) - Request[1] (1,0,2) = (2,3,0)
- Allocation[1] = Allocation[1] (2,0,0) + Request[1] (1,0,2) = (3,0,2)
- Need[1] = Need[1] (1,2,2) - Request[1] (1,0,2) = (0,2,0)
- 위 상태는 안정 상태이므로 Process[1] 의 요청을 즉시 들어줄 수 있다.
위 예시에서는 <P[1], P[3], P[4], P[2], P[0]> 순서로 진행하면 안정 순서열이 된다.